 SSL信息
SSL信息如果你体验过HTTP/2,你很可能会对HTTP/2带来的性能提升有所了解,这种提升应归因于流复用、显式流依赖和服务器推送等特性。
但有一个特性却没那么显而易见,它就是HPACK头压缩。当前版本的Apache和nginx服务器以及使用他们的edge网络和CDN网络,都不支持完整的HPACK实现。但我们已在nginx上实现了完整的HPACK,并向上溯及执行Huffman编码的部分。
在这篇博文中,我们将讨论开发HPACK的缘由,以及它带来的隐藏带宽和延时方面的好处。
背景知识
一个规则的HTTPS连接实际上是由多层模型中的几个连接的叠加。通常,人们关心的最基础的连接是TCP连接(传输层),在其上是TLS连接(传输层和应用层的混合),最后是HTTP连接(应用层)。
在HTTP/2问世之前,HTTP压缩是用gzip在TLS层执行的。由于TLS层无法知道传输的数据类型,头部和主体被无差别地压缩。也就是说,这两部分均由DEFLATE算法进行压缩。
有一个叫做SPDY的新算法是专门用来进行头部压缩的。尽管它专门为头部设计且使用了预先设置的字典,但换汤不换药,SPDY仍使用DEFLATE算法,包括动态Huffman编码和字符串匹配。
这两种算法都易受一种叫做CRIME的攻击。这种攻击能够从被压缩的头部提取加密的认证cookie:由于DEFLATE使用向后字符串匹配和动态Huffman编码,攻击者通过修改请求头部的一部分并观察这个请求在压缩中的长度变化,便能逐渐还原出整个cookie。
正因如此,大部分edge网络都不再使用头部压缩,直到HTTP/2的来临。
HPACK
HTTP/2支持一种新的头部压缩算法,叫作HPACK。HPACK的开发是着眼于防御CRIME一类的攻击,因此被认为是安全的。HPACK对CRIME的适应力强,因为它不像DEFLATE一样使用部分向后字符串匹配和动态Huffman编码。它使用以下三种压缩方法:
- 静态字典:一个具有61个常用头部字段的预定义字典,有些已预先定义了具体值。
- 动态字典:一个在连接过程中遇到的当前头部列表。这个字典大小是有限的,当有新的词条加入后,就会有旧的词条被逐出。
- Huffman编码:一个静态Huffman编码可以被用于为任何字符串编码:名称或值。这种编码是专门为HTTP响应/请求头部计算出来的-ASCII数字和小写字母的编码更短。最短的编码可能只有5位,因此最高的压缩率可以达到8:5(或者说37.5%以下)。
HPACK流
当HPACK需要以“名称:值”的格式对一个头进行编码时,它会首先查看静态和动态字典。如果找到完整的“名称:值”在字典中,它就会直接引用字典中的词条。这通常会占用一个字节,最多两个字节就够了!啥?一个完整的头部居然用一个字节就完成编码?这太疯狂了吧!
由于很多头部是重复的,这个策略有很高的成功率。例如,像:authority:www.cloudflare.com这样的头,或者有时是巨大的cookie头,这些通常都很可疑。
当HPACK不能在一个字典中匹配整个头时,它会试图寻找一个有着相同名称的头。大部分流行的头名称都会在静态表中,例如:content-encoding, cookie, etag。其余部分很可能是重复的,因此也会在动态表中。例如,Cloudflare为每个响应分配了一个唯一的cf-ray头,当这个字段的值不同的时候,名称仍能重复使用。
如果这个名称被发现,大部分情况下它就又可以用一到两个字节表示,否则这个名称就会被进行原编码或Huffman编码:采用两个中较短的那一个。对于头的值来说同理。
经测试,仅Huffman编码就节省了几乎30%的头的长度。
尽管HPACK也进行字符串匹配,但攻击者要想找到一个头的值,他们必须直接猜对整个值,而不像对于易受CRIME攻击的DEFLATE匹配那样可以逐渐靠近答案。
请求头
HPACK为HTTP请求头带来的效益比其为响应头带来的要多。其中重复的内容越多,请求头压缩得越好。
以下是两个对我们博客的请求,使用Chrome浏览器:
请求1:
:authority:blog.cloudflare.com
:method:GET
:path: /
:scheme:https
accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8
accept-encoding:gzip, deflate, sdch, br
accept-language:en-US,en;q=0.8
cookie: 297 byte cookie
upgrade-insecure-requests:1
user-agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10116) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2853.0 Safari/537.36
我用红色标出了这个可以用静态字典压缩的头。有三个字段::method:GET、:path:/、:scheme:https在静态字典中总是出现,其中每一个都会用一个字节进行编码。这样有些字段被压缩后就只有一个字节表示他们的名称: :authority、accept、accept-encoding、accept-language、cookie、user-agent都出现在静态字典中。
其他用绿色标记的部分,将使用Huffman算法编码。
未匹配到的头将被插入到动态字典中,等待下一个请求使用。
我们来看看下一个请求:
请求2:
:authority:blog.cloudflare.com
:method:GET
:path:/assets/images/cloudflare-sprite-small.png
:scheme:https
accept:image/webp,image/,/*;q=0.8
accept-encoding:gzip, deflate, sdch, br
accept-language:en-US,en;q=0.8
cookie:same 297 byte cookie
referer:https://blog.cloudflare.com/assets/css/screen.css?v=2237be22c2
user-agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10116) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2853.0 Safari/537.36
此处,蓝色的编码字段用来表示动态字典中匹配的字段。显然不同请求的大部分字段都会重复。这次又有两个字段出现在静态字典中,还有五个重复,因此出现在动态字典中,这意味着他们都可以用一到两个字节进行编码。其中一个是约300字节的cookie头,还有约130字节的user-agent。这430个字节仅用4个字节编码,压缩率达99%!
总之,对于重复的请求,只有三个短字符串会被进行Huffman编码。
这是Cloudflare的edge网络在六小时中的入口头的流量图:
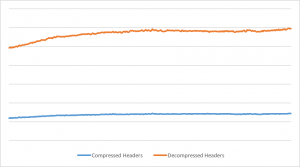
从图中我们看到,对入口的头的压缩率平均为76%。当头占了入口流量的大部分时,整个入口流量就会有很大的节省。
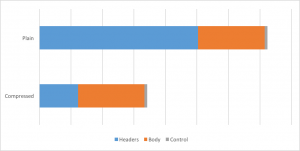
我们看到,整个入口流量因HPACK压缩而减少了53%。而相较HTTP/1,HTTP/2的入口流量只有HTTP/1的一半。
响应头
对响应头(出口流量)来说,效益稍低,但仍很惊人。
响应1:
cache-control:public, max-age=30
cf-cache-status:HIT
cf-h2-pushed:</assets/css/screen.css?v=2237be22c2>,</assets/js/jquery.fitvids.js?v=2237be22c2>
cf-ray:2ded53145e0c1ffa-DFW
content-encoding:gzip
content-type:text/html; charset=utf-8
date:Wed, 07 Sep 2016 21:41:23 GMT
expires:Wed, 07 Sep 2016 21:41:53 GMT
link: <//cdn.bizible.com/scripts/bizible.js>; rel=preload; as=script,<https://code.jquery.com/jquery-1.11.3.min.js>; rel=preload; as=script
server:cloudflare-nginx
status:200
vary:Accept-Encoding
x-ghost-cache-status:From Cache
x-powered-by:Express
第一个响应的大部分会被进行Huffman编码,其中一些字段名在静态字典找到匹配。
响应2:
cache-control:public, max-age=31536000
cf-bgj:imgq:100
cf-cache-status:HIT
cf-ray:2ded53163e241ffa-DFW
content-type:image/png
date:Wed, 07 Sep 2016 21:41:23 GMT
expires:Thu, 07 Sep 2017 21:41:23 GMT
server:cloudflare-nginx
status:200
vary:Accept-Encoding
x-ghost-cache-status:From Cache
x-powered-by:Express
蓝色仍表示匹配到动态表,红色表示匹配到静态表,绿色代表Huffman编码字符串。
在第二个响应中,12个头中的7个可能完全匹配。剩余5个中的4个的名称可以完全匹配,6个字符串将被进行有效的静态Huffman编码。
尽管2个expires头几乎是相同的,但他们只能进行Huffman压缩,因为他们不能完整匹配。
处理的请求越多,动态表就会变得越大,能被匹配的头也就越多,这使得压缩率增大。
以下Cloudflare的edge网络显示的出口处的头流量:
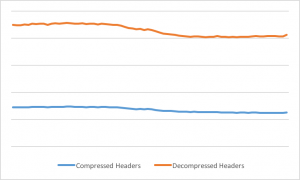
出口处的头平均压缩了69%。但全部出口流量的节省并不那么明显:
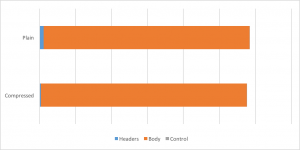
流量的节省十分细微,但即便如此,我们还是节省了整个出口HTTP/2流量的1.4%。尽管看起来不多,但仍比很多情况下的压缩率要高。这个数据在一些处理打文件的网站上被大大提高:我们测出有些网站流量节省超过15%。
测试你的HPACK
如果你安装了nghttp2,你就可以用一个叫作h2load的工具包在你的网站上测试HPACK的性能。
例如:
h2load https://blog.cloudflare.com | tail -6 |head -1
traffic: 18.27KB (18708) total, 538B (538) headers (space savings 27.98%), 17.65KB (18076) data
我们看到,在头部节省了27.98%的空间。这只是一个单独的请求,这一效果主要是Huffman编码获得的。为了测试HPACK的最大能力,我们需要发出两个请求,例如:
h2load https://blog.cloudflare.com -n 2 | tail -6 |head -1
traffic: 36.01KB (36873) total, 582B (582) headers (space savings 61.15%), 35.30KB (36152) data
如果对于两个相似请求的空间节省比例是50%或更高,那么HPACK的性能可能已经被完全发挥了。
需要注意的是额外发出请求后压缩率的提升:
h2load https://blog.cloudflare.com -n 4 | tail -6 |head -1
traffic: 71.46KB (73170) total, 637B (637) headers (space savings 78.68%), 70.61KB (72304) data
本文由Vlad Krasnov于2016年11月28日发布自Cloudflare.
