 SSL信息
SSL信息与公共电话网络不同,因特网有一个数据包交换的设计。但是这些包到底可以有多大呢?

CC BY 2.0 image by ajmexico, inspired by
这是一个老问题,关于IPv4的RFC文档很清楚地回答了这个问题。他们的想法是将该问题分解为两个不同的问题:
- 两个终端的操作系统能够处理的数据包最大是多少?
- 可以通过两个主机之间的物理连接进行安全传输的数据报的最大允许值是多少?
当一个数据包太大而不适合物理链路时,中间路由器可能会把它切割成多个小的数据报,以便使它适合物理链路。这个过程被称为“转发”IP分段,而这些较小的数据报被称为IP片段。
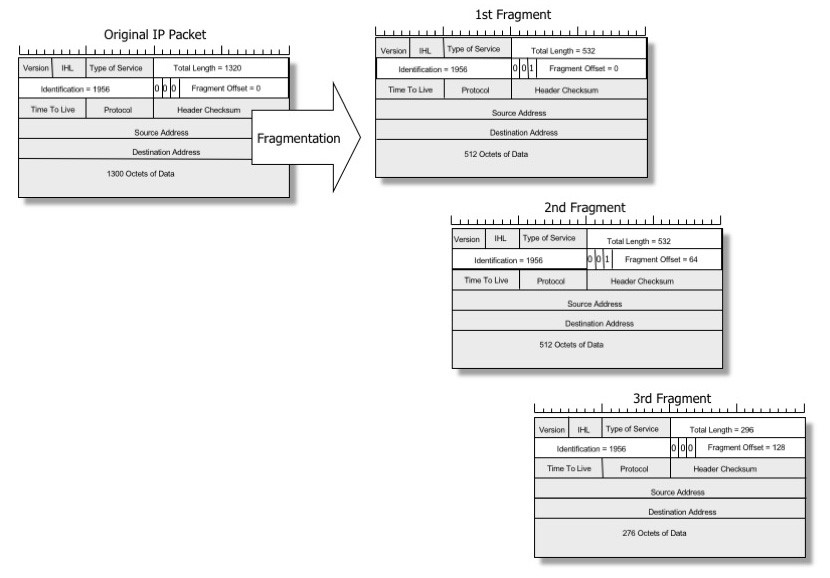
Image by Geoff Huston, reproduced with permission
IPv4规范定义了最低需求。以下描述来自RFC791文档:
每个互联网目的地都必须能够整个地或分段地接收一个576个8位字节的数据报。【……】
每个互联网模块都必须能够转发一个68个8位字节的数据报,而不需要再对其进行分段。【……】
第一个值——允许重新组合的数据包大小——通常不会有问题。IPv4将最小值定义为576字节,但是流行的操作系统可以处理非常大的数据包,通常最多可达65K字节。
第二个值要麻烦一些。所有物理连接都有固定的数据报大小限制,这取决于它们使用的特定介质。例如,帧中继可以发送46到4,470字节之间的数据报。ATM使用固定的53字节数据报,经典的以太网数据报可以在64到1500字节之间。
该规范定义了最小的需求——每个物理链路必须能够传输至少68字节的数据报。对于IPv6,最小值已经被提升到1280字节(参见RFC2460文档)。
另一方面,可以在没有分段的情况下传输的最大数据报大小没有被任何规范所定义,这个值因链路类型而异。这个值被称为MTU(最大传输单元)。
MTU定义了本地物理链路上的最大数据报大小。互联网是由非同类网络创建的,在两个主机之间的路径上可能有更小的MTU值的链路。可以在两个远程主机之间传输的最大数据包大小被称为路径MTU,这个值对于每个连接来说可能是不同的。
避免分段
有人可能会认为,构建传输非常大的数据包的应用程序并依靠路由器来执行IP分段是很好的。这并不是一个好主意。Kent和Mogul在1987年首先讨论了这种方法的问题。这里有几个亮点:
- 要成功地重新组装一个数据包,必须发送所有的片段。任何片段都不能在传输过程中损坏或丢失。但根本没有办法把丢失的片段告知传输的另一方。
- 最后一个片段几乎永远不会有最佳的大小。对于大的传输来说,这意味着通信流量的很大一部分将由非最优的较短数据报组成——这是在浪费宝贵的路由器资源。
- 在重新组装之前,主机必须在内存中保存部分片段的数据报。这为内存耗尽的攻击打开了一扇门。
- 后续的片段缺少较高层的报头。TCP或UDP报头只出现在第一个片段中。这使得防火墙不可能根据源端口或目标端口等标准对片段数据进行过滤。
在以下这些Geoff Huston的文章中,可以找到一种更详细的IP分段问题的描述:
不要分段——ICMP数据包太大了
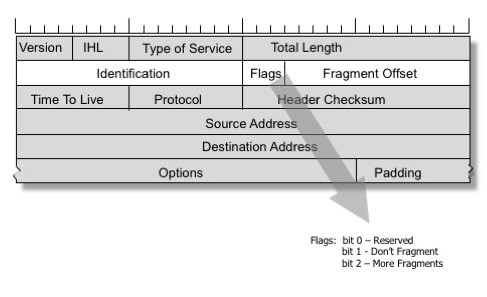
Image by Geoff Huston, reproduced with permission
解决这些问题的方法包括在IPv4协议中。发送方可以在IP报头中设置DF(不要分段)标记,请求中间路由器永远不要对数据包执行分段。相反,一个带有较小MTU值的链路的路由器将发送ICMP消息“向后”,并通知发送方为该连接减少MTU值。
TCP协议总是设置DF标志。网络堆栈会仔细检查进来的“数据包太大”的ICMP消息,并跟踪每一个连接的“路径MTU”特征。这种技术被称为“路径MTU发现”,它通常主要用于TCP协议,尽管它也可以应用于其他基于IP的协议。能够发送ICMP“数据包太大”的消息对于保持TCP堆栈的最佳工作状态是至关重要的。
互联网实际上是怎样工作的
在一个完美的世界里,互联网连接设备将会彼此合作并正确处理分段数据报和相关的ICMP数据包。但实际上,IP片段和ICMP数据包经常被过滤掉。
这是因为现代互联网比36年前要复杂得多。今天,基本上已经没有人直接接入公共互联网了。
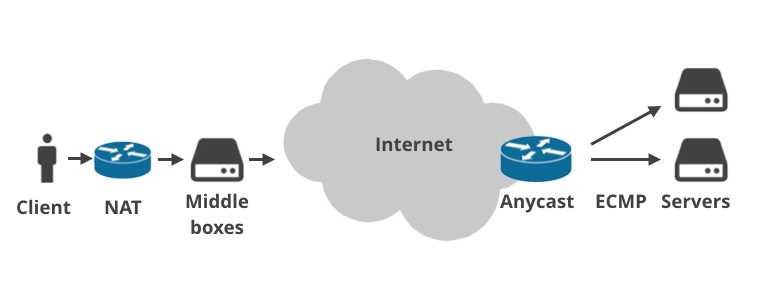
客户设备通过使用NAT(网络地址转换)的家庭路由器进行连接,并且通常强制执行防火墙规则。在数据包路径上安装着不止一个NAT(例如,电信级别的NAT),而且这种情况正在变得越来越常见。然后,数据包到达了ISP的基础设施,那里有ISP的“中间盒子”。他们在通信上执行各种奇怪的东西:强制执行计划封顶、限制连接、执行日志记录、劫持DNS请求、执行政府规定的网站禁令、强制透明缓存或者以某种其他不可思议的方式“优化”通信。中间的箱子尤其会被移动通信公司使用。
类似地,服务器和公共互联网之间常常有多个层。服务提供商有时使用Anycast BGP路由。也就是说,他们从世界各地的多个物理位置处理相同的IP范围。另一方面,在一个数据中心,使用ECMP(等价多路径)路由来实现负载均衡正在变得越来越流行。
客户机和服务器之间的每一层都可能导致路径MTU问题。请允许我用四个场景来说明这个问题。
1.客户端->服务器DF+/ICMP
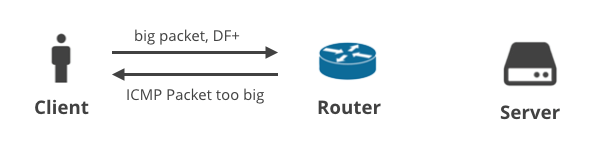
在第一个场景中,客户端使用TCP向服务器上传一些数据,因此在所有数据包上都设置了DF标志。如果客户端未能预计到合适的MTU,则中间路由器将丢弃大数据包,并将ICMP“数据包太大”的通知发送回客户端。这些ICMP数据包可能会被错误配置的客户NAT设备或ISP的中间盒子所丢弃。
根据Maikel de Boer和Jeffrey Bosma发表的论文,从2012年起,大约由5%的IPv4和1%的IPv6主机屏蔽了入站ICMP数据包。
我的经验也证实了这一点。因为明显的安全优势,ICMP消息确实经常会被放弃,但这个问题相对容易解决。一个更大的问题是,某些移动互联网服务提供商有奇怪的中间盒子。这些中间盒子常常完全忽略ICMP,并执行非常激进的连接重写。例如,波兰Orange电信公司网站不仅会忽略入站的“数据包太大”ICMP消息,还会重写连接状态,并将MSS夹在不可磋商的1344字节中间。
2. 客户端->服务器DF-/分段
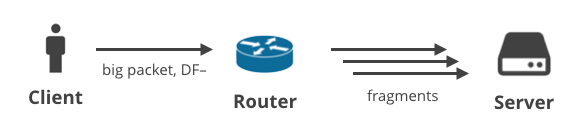
在接下来的场景中,客户端使用除TCP以外的某个协议来上传一些数据,这将使DF标记被清除。例如,这可能是一个用户使用UDP协议进行游戏,或者进行一个语音呼叫。大的出站数据包在路径上的某个点可能会被分段。
我们可以通过运行带有巨大负载的ping命令来模拟一下这个场景:
$ ping -s 2048 facebook.com
这一特殊的ping命令将会运行失败,因为它的的有效负载将超过1472字节。任何更大的尺寸都会被分段,无法正确地发送。服务器可能错误处理片段的原因有很多,但是一个很普遍的问题是ECMP负载均衡的使用。由于ECMP的散列运算,第一个包含协议报头的数据报可能会被负载均衡到不同的服务器,而不是其他的片段,从而阻止了重新组合。
关于该问题的更详细讨论,请看:
- 谷歌是怎样试图用Maglev L4负载均衡器来解决ECMP分段问题的。
此外,服务器和路由器的错误配置是一个很重要的问题。根据RFC7852文档的说法,由30%到55%的服务器会丢弃包含片段报头的IPv6数据报。
3. 服务器->客户端DF+/ICMP
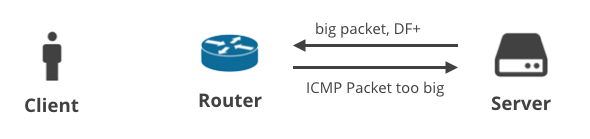
下一个场景是客户端通过TCP协议下载一些数据。当服务器无法预计正确的MTU时,它应该会收到一个ICMP“数据包太大”的消息。这很简单,对吧?
遗憾的是,这也不是由于ECMP路由的原因。这条ICMP消息很可能会被发送到错误的服务器——ICMP数据包的5元组散列与问题连接的5元组散列不匹配。Cloudflare在过去写过这个,并开发了一个简单的用户空间守护进程来解决这个问题。它的工作原理是向所有ECMP服务器发送入站ICMP“数据包太大”的通知,希望有问题的连接可以看到它。
此外,由于Anycast路由,ICMP可能会被全部发送到错误的数据中心!互联网路由通常是不对称的,而来自一个中间路由器的最佳路径可能会将ICMP数据包引导到错误的位置。
错过ICMP“数据包太大”的通知可能会导致连接停止和超时。这通常被称为PMTU黑洞。为了解决这种悲观的情况,Linux系统实现了一个解决方案——MTU探测,见RFC4821。MTU探测尝试自动识别由于错误的MTU而丢弃的数据包,并使用启发式方法进行调整。这个功能是通过一个sysctl命令来控制的:
$ echo 1 > /proc/sys/net/ipv4/tcp_mtu_probing
但是,MTU探测也并非没有它自己的问题。首先,由于MTU的问题,它往往将与阻塞有关的数据包错误归类。长时间运行的连接往往以减少MTU结束。其次,Linux系统没有实现对IPv6的探测。
4. 服务器->客户端DF-/分段
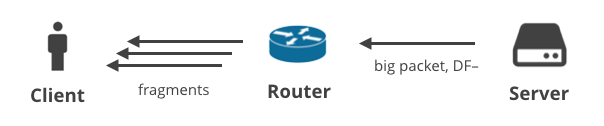
最后,还有一种情况是,服务器使用一个非TCP协议发送大数据包,有清晰的DF位。在这个场景中,大的数据包将在通往客户端的路径上被分段。这种情况用大的DNS响应来说明是最好的。下面是两个DNS请求,它们将生成大量的响应,并作为多个IP片段被发送给客户机。
$ dig +notcp +dnssec DNSKEY org @199.19.56.1
$ dig +notcp +dnssec DNSKEY org @2001:500:f::1
这些请求可能由于前面已经提到的错误配置的家庭路由器、损坏的NAT、损坏的ISP装置或过于严格的防火墙设置而失败。
根据Boer和Bosma研究,大约6%的IPv4和10%的IPv6主机会拦截入站数据报片段。
以下是一些关于影响DNS的分段问题的更多详细信息的链接:
然而,互联网仍然正常工作!
这么多东西都出了问题,互联网怎么还能正常运转呢?

CC BY-SA 3.0, source: Wikipedia
这主要是由于以太网的成功。公共互联网上的大多数链接都是以太网(或从它派生而来),并支持1500字节的MTU。
如果你盲目地假设MTU是1500字节,你会惊讶地发现它会运行得很好。互联网之所以继续正常工作,主要是因为我们都在使用1500字节的MTU,很少需要进行IP分段和发送ICMP消息。
这使我们不再需要研究如何对使用非标准的MTU的连接进行不常见的设置。VPN和其他网络隧道软件必须小心确保片段和ICMP消息正常工作。
这在IPv6的世界中尤其明显,在那里,许多用户通过隧道连接。在两种方式中都使用健康的ICMP段是非常重要的,特别是在IPv6的分段已基本上不能正常运转的时候(我们引用了两个消息源,声称10%到50%的IPv6主机都会阻止IPv6片段报头)。
由于在IPv6中路径MTU问题是如此普遍,许多IPv6服务器都将路径MTU值限制到协议规定的最小值1280字节。这种方法牺牲了一点性能,获得了最佳的可靠性。
在线ICMP黑洞检测工具
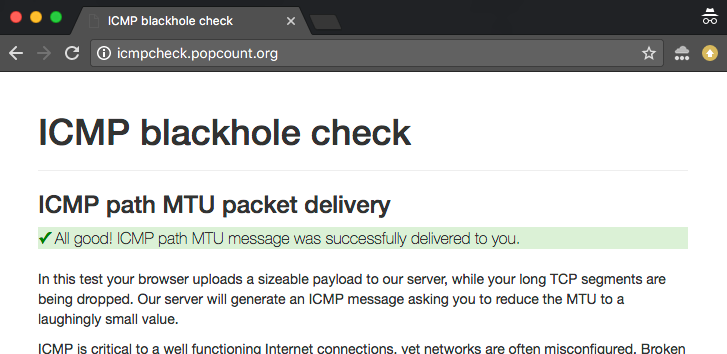
为了帮助探索和调试这些问题,Cloudflare建立了一个在线检查工具。你可以找到两个版本的测试:
- IPv4版本:http://icmpcheck.popcount.org
- IPv6 版本:http://icmpcheckv6.popcount.org
这两个网站执行两个测试:
- 第一个测试将向你的计算机发送ICMP消息,目的是将路径MTU值减小到一个极低的值。
- 第二个测试将把片段数据报发回给你。
在这两项测试中都获得一个“通行证”应该能给你适当的保证,那就是网络上你的那一端的线路运行良好。
从命令行运行测试也很简单,在服务器上运行:
perl -e "print 'packettoolongyaithuji6reeNab4XahChaeRah1diej4' x 180" > payload.bin
curl -v -s http://icmpcheck.popcount.org/icmp --data @payload.bin
curl -v -s http://icmpcheckv6.popcount.org/icmp --data @payload.bin
这将会把到我们的服务器的路径MTU值降低到905字节。你可以通过查看路由缓存表来验证这一点。在Linux系统中你需要这样做:
ip route get `dig +short icmpcheck.popcount.org`
可以这样在Linux系统中清除路由缓存:
ip route flush cache to `dig +short icmpcheck.popcount.org`
第二个测试验证了片段是否被正确地发送到客户端:
curl -v -s http://icmpcheck.popcount.org/frag -o /dev/null
curl -v -s http://icmpcheckv6.popcount.org/frag -o /dev/null
概述
在这篇博客中,我们描述了在互联网上探测路径MTU值的问题。ICMP和片段数据报在连接的两端经常被拦截。客户端可能会遇到错误配置的防火墙、NAT设备,或使用那些主动地对连接进行拦截的ISP。客户端还经常使用VPN或IPv6的隧道,这些配置不当的隧道可能导致路径MTU问题。
另一方面,服务器越来越多地依赖于Anycast或ECMP。这两种东西,以及路由器和防火墙的错误配置,通常会是ICMP和片段数据报被丢弃的原因。
最后,我们希望在线测试是有用的,可以让你对你的网络的内部工作原理有更深入的了解。该测试还有一些有用的tcpdump语法示例,有助于更深入的理解。愿你愉快地调试好网络!
本文转载并翻译自cloudflare博客,由Marek Majkowski于2017.08.原文点击此处。